
Published 2022. 10. 13. 21:37
Date: 2022.10.13
출처가 명시되어 있지 않은 모든 이미지의 지식재산권은 재단법인 네이버커넥트에 귀속됩니다.
Visualizing CNN
What is CNN visualization
- CNN은 그 내부에서 일어나는 연산을 이해하기 어렵기 때문에, 자주 blackbox라고 표현된다.
- CNN의 내부에선 어떤 연산이 일어나며, 왜 잘 작동하고, 어떻게 개선될 수 있을까?
- 아래의 예시는 deconvolution을 이용하여 visualization을 시도한 결과이다. low layer (input과 가까운 layer)에서는 간단한 feature를 탐지하며, high layer(output과 가까운 layer)에서는 좀 더 의미 있는, 복잡한 feature를 탐지한다.
Vanilla Example: Filter Visualization
- 아래의 예시는 AlexNet의 첫번째 layer의 filter와, filter에 의해 activation된 결과를 visualization 한 것이다. (필터는 3 channel이므로 컬러, activation된 결과는 1차원이므로 흑백으로 표현된다.)
- 방향을 보는 filter도 있고, 색상을 보는 filter도 있다.
- 왜 첫번째 layer의 filter만 visualization 했을까?
- 첫번째 layer의 filter만 입력 이미지에 맞춰 3 channel이고, 이후의 filter들은 더 높은 차원이기 때문에 visualization을 하기가 어렵다.
- 또, visualization을 해봤자 그 filter는 단독으로 사용되는 것이 아니라, 이전 layer들의 filter를 거친 정보들을 다시 filtering 하는 것이기 때문에 전체적인 의미를 파악하는 것이 불가능하다.

How to Visualize Neural Network
- Neural network의 visualize는 model 전체의 특성을 파악하는데 강점을 둔 방법(Analysis of model behaviors)들과 하나의 입력 데이터가 내놓은 결과에 대해 왜 그런 결과를 내는지를 파악하는 방법(Model decision explanation)들이 있다.

Analysis of Model Behaviors
Embedding feature analysis (for High level feature)
Nearest Neighbors in a feature space
- 가지고 있는 data들을 모두 embedding 한 후, query image를 넣어 유사한 이미지를 뽑았을 때, 아래 파란색 상자의 예시처럼 단순히 고전적인 방법 (각 pixel간의 값을 계산하는 방식)으로는 비슷하다고 판단할 수 없는 경우가 존재한다.
- 즉, model이 이미지의 (semantic) concept을 잘 학습했다는 것을 알 수 있다.

Dimensionality Reduction - t-SNE (t-distributed stochastic neighbor embedding)
- Data를 feature space로 embedding 한 후, t-SNE를 통해 dimension을 낮추었을 때 같은 category의 data끼리 잘 clustering이 된다면 model이 data feature를 잘 표현한다고 생각할 수 있다.
- 좀 더 자세히 살펴보면, 3, 8, 5에 해당하는 data들이 가깝게 위치하고 있다. 이는 model이 이 class들이 유사하다고 생각하고 있다는 것을 추측할 수 있다.

Activation investigation
Layer Activation - Behaviors of mid-to high-level hidden units
- AlexNet의 5번째 conv layer의 138번째 channel을 적당히 thresholding하고 mask로 만들어서 영상에 overlay 하니 아래와 같은 결과를 얻었다.
- 이와 같은 방법을 통해 각 layer의 hidden node들의 역할을 찾을 수 있다.

Maximally Activating Patches - Patch Acquisition
- 특정 filter를 최대로 activating시킨 image patch를 visualization한 결과이다. 그 과정은 아래와 같다.
- Pick a channel in a certain layer
- Feed a chunk of images and record each activation value (of the chosen channel)
- Crop image patches around maximum activation values

Class Visualization - Gradient Ascent
- Data를 사용하지 않고, network가 내재하고 있는, 기억하고 있는 image를 분석하는 방법
- 최적화를 통해서 특정 영상을 찾아간다.
$$I^{\ast} = \underset{I}{argmax}f(I) - Reg(I)$$
- 이때, $Reg(I)$를 Regularization term 이라 부른다.
- Gradient Descent를 통해 $I$를 계속 update 하다보면 $I$가 더 이상 영상의 형태를 띄지 않을 수 있다. (ex. 값의 범위가 0~255 또는 normalization 이후 0~1의 범위를 벗어나지만, model은 이것이 dog라고 정확히 판단하는 경우)
- 이를 막기 위해 $I$의 $L_2$ norm을 Regularization Term으로 사용하게 된다.
$$I^{\ast} = \underset{I}{argmax}f(I) - \lambda \begin{Vmatrix}I\end{Vmatrix}^2_2$$
- $I$를 바꿔가며, 해당 이미지가 class: dog에 속할 확률을 maximize하는 $I$를 찾고싶다!
- $I$를 바꿔가며 $f(I)$를 maximize해야 하기 때문에 gradient ascent 라고 불리지만, 사실 부호를 반대로 바꾸고 minimize하는 문제로 바꿀 수 있으므로 gradient descent랑 똑같다.
- 그 과정은 아래와 같다. (진짜 gradient descent랑 똑같음)
- Get a prediction socre (of the target class) of a dummy image (blank or random initial).
- Backpropagate the gradient maximizing the target class score with respect to the input image.
- Update the current image.
- Get a prediction socre (of the target class) of a current image.
- Repeat 2-4.
- 다양한 random noise를 model에 input으로 넣어주어 model이 잠재적으로 생각하고 있는 해당 class의 이미지를 엿볼 수 있다.

Model Decision Explanation
Saliency Test
Occlusion Map
- Mask의 위치에 따라 model의 예측값 역시 바뀌게 된다. 즉, mask를 이동시켜가며 예측값이 가장 낮은 부분을 찾는다면, 그 부분이 model이 해당 class인지 아닌지를 판단하는 과정에서 가장 중요한 역할을 하는 영역일 것이다.

- 이러한 개념에서 탄생한 것이 Occlusion Map이다.

via Backpropagation
- 앞서 설명한 Gradient Ascent를 이용한 방법과 비슷하지만, input으로 noise가 아닌 특정한 image를 넣어준다는 차이가 있다. 즉, 앞서 설명한 방법은 전반적인 model의 인지능력에 대한 분석을, 이 방법은 특정 data를 model이 해석 방법에 대한 분석을 제공한다. (쓰고 나니 말이 비슷해서 더 헷갈린다 ㅠㅠ.)

- 그 과정은 아래와 같다.
- Get a class score of the target source image
- Backpropagate the gradient of the class score with respect to input domain
- Visualize the obtained gradient magnitude map (optionally, can be accumulated)
- gradient의 절댓값 또는 제곱을 사용하게 된다. 그 이유는 gradient의 크기가 model의 sensitivity를 표현하기 때문 (gradient의 크기는 해당 이미지의 pixel이 얼마나 바뀌어야 하는가를 의미하므로, gradient의 크기가 크다는 것은 부호와 관계없이 판단에 중요한 역할을 하는 위치임을 의미한다.)
Backpropagate Features
Rectified Unit (Backward Pass)
- 기존에는 model의 forward pass에서 activation이 0보다 작았던 값들의 위치를 masking 한 후, backward pass에서 해당 위치의 gradient 값들을 0으로 만들어 통과시켰다.
- But, 여기서는 deconvolution된 Gradient 값에 ReLU를 씌운다.
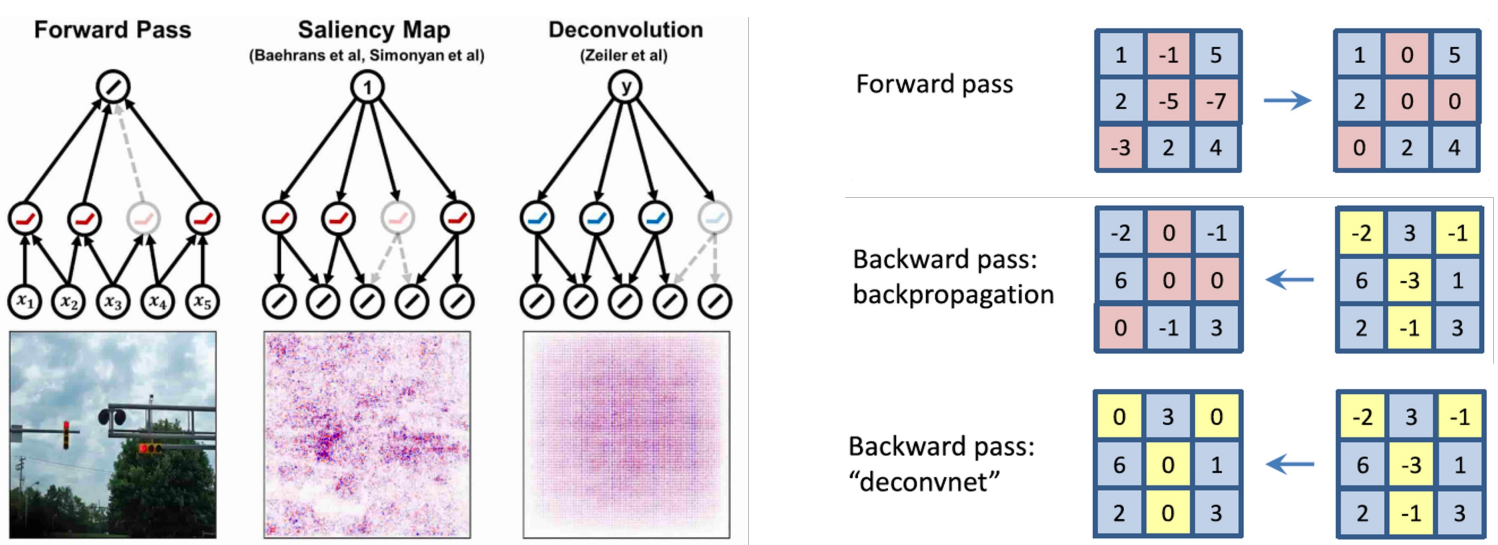
- 이를 수식으로 표현하면 아래와 같다.
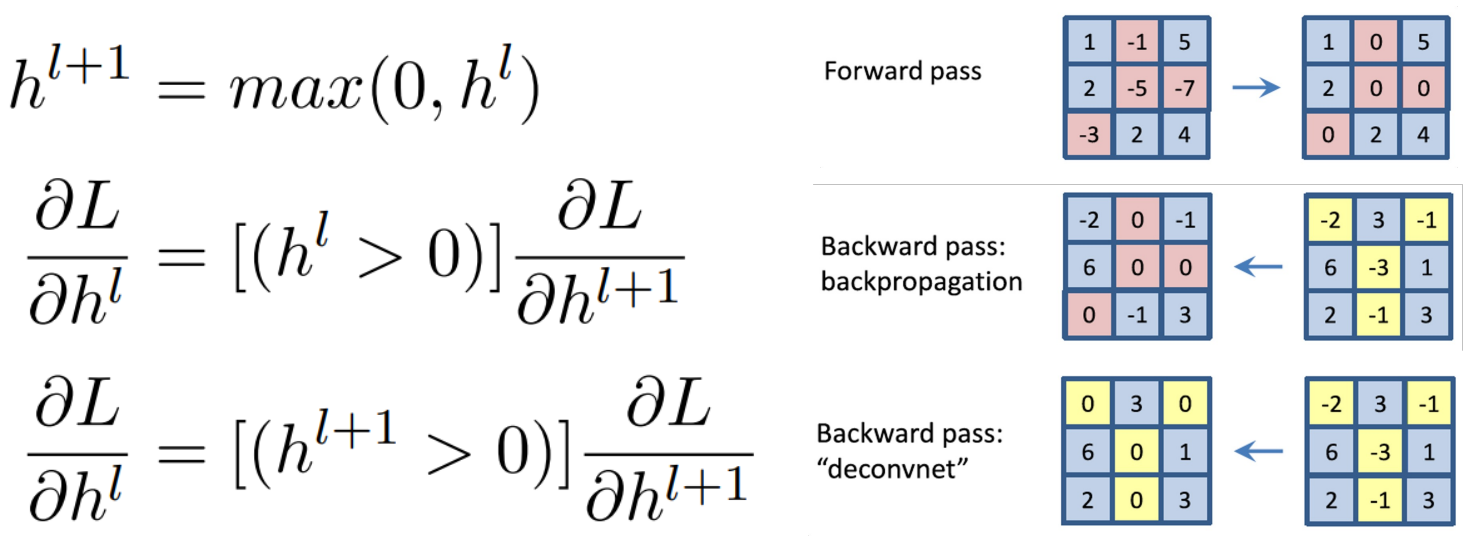
- But, 이렇게 되면 gradient를 역전파 하는 것도 아니고, 수학적으로도 아무런 의미를 갖지 않는 연산이다.
- 이왕 이렇게 된거 아무렇게나 해버리자?!

- Forward, Backward에서 0보다 작은 값을 가졌던 값들을 모두 0으로 만들어버리자! 역시 이것도 gradient 역전파의 의미도 없고, 수학적인 의미도 없으니 찾으려 하지 말자.
- But, 결과는 잘 나온다.

- 이제, 결과로부터 앞서 말한 연산의 의미를 찾아보자면, forward, backward pass에서의 mask를 모두 사용하는 것이 결과에 긍정적인 영향을 미친 양수들만 참조하는 것이라고 생각할 수 있다.
- (forward pass에서 0보다 작았던 위치를 backward에서 masking 하는 것은) forward 과정에서 activation이 0보다 작다는 것은 prediction에 부정적인 영향을 미쳤다는 것을 의미하므로 없앤다.
- (backward pass에서 0보다 작은 값들을 masking 하는 것은) gradient가 0보다 작다는 것은 해당 값을 더 작게 만드는 방향으로 update 해야 한다는 것을 의미하고, 이 역시 위와 같은 맥락에서 없애준다.
- 결과에 긍정적인 영향을 미치는 것만 남겼으니, 당연히 특징이 잘 보이지 않겠냐? 라는 내용이다.
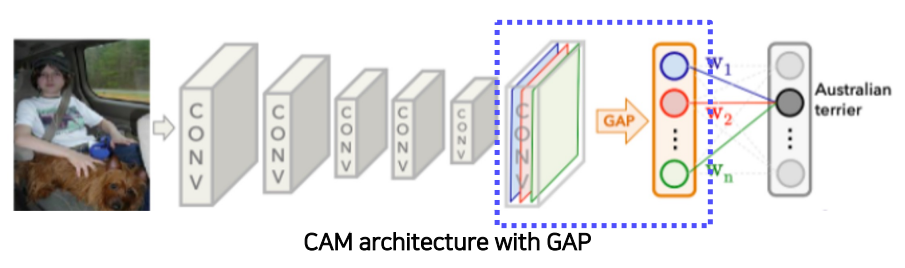
Class Activation Mapping
- Final decision에서 image의 어떤 부분이 얼마나 기여했는가를 visualize 해준다.

- Class Activation Map을 확인하기 위해서는, CNN 구조의 마지막에 FC Layer 대신 Global Average Pooling 이후, 하나의 FC layer만을 통과하는 구조로 수정 후, 다시 학습시켜주어야 한다.
- 이때, 각 class에 해당하는 score는 아래와 같이 계산될 수 있다.

- 여기서 모든 연산은 linear하므로, 그 순서를 바꿔줄 수 있다.
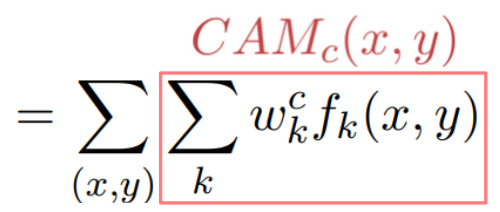
- 이때, $f_k$는 global average pooling을 적용하기 전이므로 spatial한 정보가 남아있다. 이를 영상처럼 생각하고 visualize하면 CAM을 확인할 수 있다.
- 놀라운 점은, classification task에 대한 dataset을 이용하니 당연히 물체의 위치에 대한 어떤 정보도 주어지지 않았는데도 불구하고, 판단의 기준이 되는 물체의 위치가 정확하게 activation 된다는 점이다.
- 이렇게 activation된 정보를 활용하면 object detection에도 활용할 수 있다. 이렇게 object detection과 같이 정교한 task를 좀 더 rough한 image classification task의 data를 활용하여 해결하는 것을 weakly supervised learning 이라고 부른다.
- But, architecture의 마지막에 Global Average Pooling과 하나의 FC layer 만을 사용해야하고, 이로인해 학습을 다시 해야 한다는 점이 단점이다.
Grad-CAM
- original model의 구조를 바꾸지 않고도, CAM을 사용할 수는 없을까? 있다! Grad-CAM의 등장으로, pre-trained model을 재학습시킬 필요가 없어졌다.

- 그 Grad-CAM을 생성하는 구조는 아래와 같다.

- CAM의 핵심 아이디어는, $w_k^c$를 구하는 방식이었다. $f_k(x,y)$는 이미 알고 있으니 weights만 구하면 되는데, Global Average Pooling 없이 어떻게 weights를 구할 수 있을까?
- Silency Map을 구하는 방식과 유사하다!
- gradient를 backpropagation 시킬 때, input image 까지 가는 것이 아니라, 우리가 관심을 가지고 있는 activation map까지만 backpropagation 시킨다.
- 이후, channel 축으로 Global Average Pooling을 적용하여 각 channel의 gradient 성분의 크기를 구하고, 이를 activation map을 계산하기 위한 weights($\alpha_k^c$)로 사용한다.

- 이를 선형결합하고, 다시 ReLU를 적용하면 Grad-CAM을 얻을 수 있다.
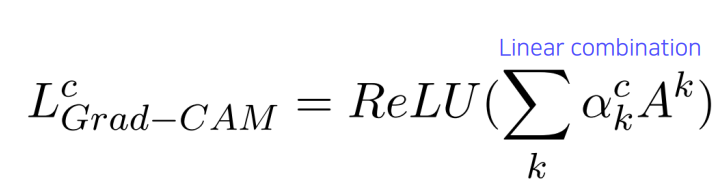
- Grad-CAM은 뒤에 어떤 종류의 network가 붙던 상관없이 생성할 수 있다.
- 앞서 설명한 Guided Backprop(sensitive 하고 high-frequency의 정보)과 Grad-CAM(smooth하고 rougph한 class 관련 정보)의 값을 곱하여 Guided Grad-CAM을 만들어서 사용하기도 한다.

SCOUTER
- 최근에는 Grad-CAM 보다 더욱 발전하여, 왜 해당 class에 해당하는가 뿐만 아니라, 왜 해당 class에 속하지 않는가에 대한 activation 정보를 얻을 수도 있다.

결론
- CNN을 해석하기 위한 Visualization 방법들을 통해 CNN 내부를 직접 해석할 수는 없지만, 살짝의 조작을 통해 사람들이 해석가능한 형태의 정보를 뽑아낼 수 있다.
- 즉, 우리가 의도하지는 않았지만 CNN은 학습 과정에서 사람들도 공감할 수 있는 지식을 자발적으로 잘 학습한다.
- 해석이 가능하면 응용도 가능하다.
22.10.13
- 오늘은: (4, 5강 블로그 정리 및 복습) + (과제 1, 2, 3 한번 더 돌려보고 제출) + (피어세션) + (마스터세션: 안수빈 마스터) + (Data Viz 4강 ~ 5강 듣는 중)
- 자기 전에: (6강 블로그 정리 및 복습)
- 내일은: (Data Viz 다 듣기) + (피어세션 : 과제 1, 2, 3 리뷰) + (팀을 찾습니다 둘러보기) + (스페셜 피어세션) + (피어 세션) + (오피스 아워) + (트랜스포머 복습) + (멘토링)
- 뭐했다고 벌써 11시지? 사실 저녁 먹고 나서 좀 쉬려고 했는데, 그럼 오늘의 회고를 적을 블로그 글이 없어서 거의 반강제로 CNN Visualization을 복습했다. 근데, 재밌다. 처음에 들을때는 method에서 다음 method로 물 흐르듯이 넘어가서 뭐가 뭔지 구분을 못하겠었는데, 다시 들어서 그런건지 블로그에 목차를 정리하면서 들어서 그런건지는 모르겠지만 이해가 잘 된다. 이걸 듣다보니, 2년 전에 딥러닝 개론 들을 때 2 layer CNN + Class Activation Map을 딥러닝 프레임워크 없이 다 짜라고 했던 과제가 생각난다. CAM이 내가 생각했던 거랑은 구조가 살짝 달랐다. 틀리게 짰던 것 같은데 왜 만점을 줬을까? 이해도 잘못했지만, 코딩도 잘못해서 운 좋게 맞았던 건가?
- 오늘 갑자기 생긴 질문: ViT에서 image를 patch 단위로 쪼개서 넣어주는 이유는 뭘까? 어차피 patch를 잘라서 flatten 후 raster order scan 순서대로 concat 해서 Linear Layer에 넣어주는데, 그러면 이미지 전체에 대한 spatial한 정보는 사라지는 거 아닌가? 어차피 spatial한 정보를 버릴거라면, 이미지를 그냥 row 단위로 잘라서 concat 한 후 Linear Layer에 넣어주는거(= flatten 후 Linear)랑 다른게 뭘까? 다른게 있으니까 patch 단위로 쪼개서 넣어주는 방식을 사용했겠지? 언젠가 이 글을 다시보면서 '이때는 이런 멍청한 생각을 다했네 ㅋㅋ' 하고 넘어가는 날이 오면 좋겠다~
- 오프라인 스몰톡에 다녀온 후로, 팀 building에 대한 조급함이 생겼다. 고맙게도 먼저 관심을 가지고 연락주신 분들도 계셨지만, 섣불리 같이 하겠다는 말을 하지는 않았다. 내가 뭘 하고싶은지 아직 확실히 못 정하기도 했고, 그 분들 역시 확실한 주제를 들고 오신건 아니었다. 차라리 확실한 주제를 제시해주셨다면 확답을 드렸을텐데, 그냥 좀 더 생각해보자는 식으로 말씀드렸다. 목적없이 뭉쳐있다고 한 팀이 되는건 아니니까. 같은 주제에 정말 관심이 있거나, 부스트캠프가 끝난 후의 목적이 같은 5명이 한 팀으로 모이는게 애초에 가능하기는 한 걸까? level 1보다 훨씬 오래가는 팀이다보니 신중하고 조심스럽지만, 마냥 기다릴 수도 없다. 어렵다 어려워.