Date: 22.10.18
출처가 명시되어 있지 않은 모든 이미지의 지식재산권은 재단법인 네이버커넥트에 귀속됩니다.
Conditional Generative Model
Conditional Generative Model
- 주어진 조건(condition)에 따라 image를 생성한다!
- 기존의 generative model은 noise를 입력받아 random한 sample을 생성한다.
- Conditional generative model은 noise와 condition을 함께 입력 받아, 주어진 condition 내에서 random한 sample을 생성한다.
- 그 예시는 아래와 같다.
- Image 외에도, audio super resolution, machine translation, article generation with title 등의 application이 존재한다.
- GAN과 Conditional GAN은 각각 아래와 같은 구조를 갖는다.

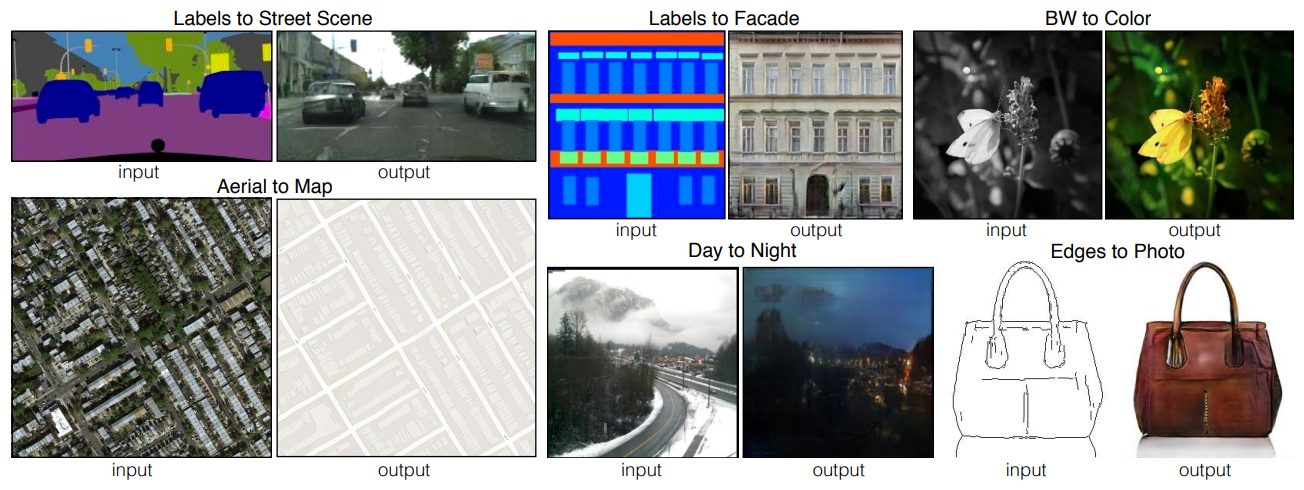
Conditional GAN and Image Translation
Image-to-Image Translation
- Image를 다른 image로 translation 한다.
- Example: Style transfer, Super resolution, Colorization, etc.

Example: Super Resolution
- Input: Row resolution image
- Output: High resolution image

- 이 역시, 아래와 같은 conditional GAN의 구조를 통해 구현할 수 있다.

- 이때, conditional GAN에서는 MAE(L1 loss, Mean Absolute Error) 또는 MSE(L2 loss, Mean Square Error)를 사용하던 기존의 regression 모델들과는 다른 Loss를 사용한다.
- 왜? ㅡ> MAE/MSE 는 결국 pixel들간의 intensity 차이로 error를 계산하기 때문에, 학습 과정에서 safe average-looking image(blurry한, sharp하지 못한 image)를 생성하는 방향으로 학습된다.
$$MAE = \frac{1}{n}\sum_{i=1}^{n}\begin{vmatrix}y_i-\hat{y}_i\end{vmatrix}$$
$$MSE = \frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y}_i)^2$$
- 이와 달리, GAN loss는 implicit하게 real인지 fake인지를 비교한다.

- MAE/MSE의 "averaging answer"의 의미는 아래와 같다.
- 주어진 Task는 주어진 image를 colorizing 하는 것이며, real image는 반드시 "black" or "white"이다.
- 이때, L1 loss, L2 loss를 사용하면 gray image를 생성하게 된다. ("black"과 "white"의 average)
- But, GAN loss를 사용하면 gray image는 discriminator를 통과할 수 없기 때문에, "black" or "white" output을 만들어 낸다.

- 위에서 보았듯이, MSE를 사용한 SRResNet보다 GAN loss를 사용한 SRGAN에서 더 realistic하고 sharp한 image를 생성해낸다는 것을 알 수 있다.
Image Translation GANs
Pix2Pix
- Image-to-Image Translation with Conditional Adversarial Networks, 2017, CVPR
- Loss function of Pix2Pix = GAN loss + L1 loss
$$G^\ast=arg\underset{G}{min}\underset{D}{max}L_{cGAN}(G,D)+\lambda L_{L1}(G)$$
$$L_{cGAN}(G,D)=\mathbb{E}_{x,y}[logD(x,y)]+\mathbb{E}_{x,z}[log(1-D(x,G(x,z)))]$$
$$L_{L1}(G) = \mathbb{E}_{x,y,z}[\begin{Vmatrix}y-G(x,z)\end{Vmatrix}_1]$$
- 위의 식에서 $x$는 input (condition), $y$는 ground truth, $z$는 noise를 의미한다.
- $L_{cGAN}(G,D)$에서 $z$와 함께 $x$도 주어진다는 점이 기존 GAN의 loss와 다른점. 나머지는 기존 GAN의 loss와 동일하다.
- 위에서 $L_1$ loss를 그렇게 욕하더니, 왜 쓰냐?
- 첫 번째로, $L_{cGAN}(G,D)$에서는 x와 y를 직접 비교하지 않는다. 이로 인해 $L_1$ loss만 사용하면 y와 비슷한 결과를 얻을 수 없다.
- 두 번째로, GAN loss만 가지고 모델을 학습시키는 것은 굉장히 어렵다. (학습이 불안정함 ㅠㅡㅠ). 그래서 guide 역할을 해주는 $L_1$ loss를 추가했다!
- 결과를 보자. 실제로 $L_1$ Loss만 사용하면 굉장히 blurry한 output을 생성해내고, $L_1$ Loss + $L_{cGAN}(G,D)$을 사용하였을 때 가장 compelling한 colorization 성능을 보인다.
- But, grayscale을 보이는 실패한 경우(last row)도 존재한다.


CycleGAN
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017, ICCV
- Pix2Pix에서는 {x, y}의 pairwise data가 필요하지만, 이러한 형태의 dataset을 모으는 것은 쉽지 않다.
- CycleGAN에서는 {x1, x2, ...}, {y1, y2, ...} 형태의 data를 사용하여 domain에서 다른 domain으로의 translation이 가능하다.

- Loss function of CycleGAN = GAN loss (in both direction) + Cycle-consistency loss
$$L_{CycleGAN} = L_{GAN}(X\underset{}{\rightarrow}Y) + L_{GAN}(y\underset{}{\rightarrow}X) + L_{cycle}(G, F)$$
- 이때, G, F는 모두 Generator이다.
- GAN Loss: image의 domain을 A에서 B, B에서 A로 보낼 때의 GAN Loss
- CycleGAN에서는 두 개(A에서 B 방향, B에서 A 방향)의 GAN Loss를 갖는다.
- GAN Loss: $L(D_X)+L_(D_Y)+L(G)+L(F)$
- G, F는 Generator, $D_X, D_Y$는 Discriminator이다.

- Cycle-consistency Loss: x를 A에서 B로 보냈을 때 y가 되었다면, y를 B에서 A로 보내면 x가 되어야 한다! (But, supervision은 제공되지 않는다. Dataset이 pairwise 하지 않았으니, 당연한 소리. ㅡ> self-supervision)

- Cycle-consistency Loss는 왜 필요할까?
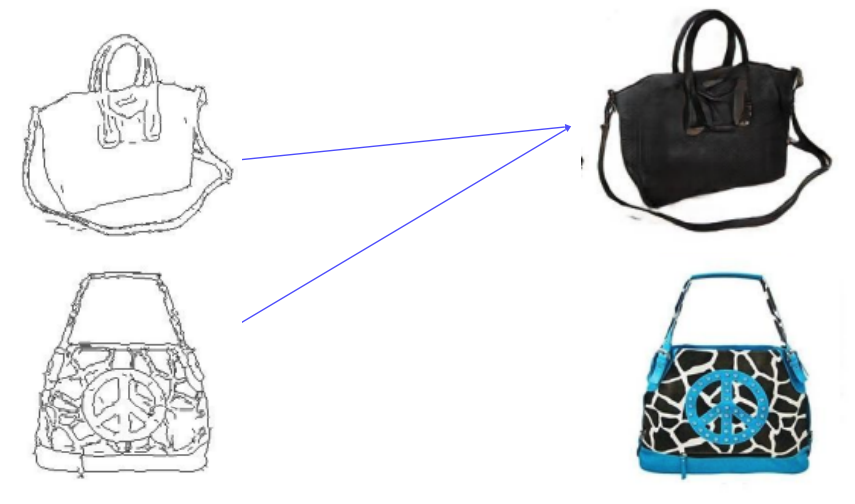
- Cycle-consistency Loss가 없다면, input에 상관없이 하나의 output을 뱉어내는 방향으로 학습하게 된다. (아래 예시처럼 실제로 domain이 바뀌긴 한다.)
- Cycle-consistency Loss로 인해, Generating 과정에서 image의 contents를 preserve하게 된다.
Perceptual Loss
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution, 2016, ECCV
- GAN은 학습하기 어렵다. (Discriminator와 Generator를 번갈아가며 학습시키는 alternating training이 필요함.)
- 구현이 귀찮은 건 그렇다 쳐도, 진짜 학습시키기가 너무 너무 너무 너무 힘들더라.
- 좀 더 쉬운 방법 없을까? ㅡ> perceptual loss 등장
- Observation: pre-trained classifier의 filter response는 인간의 visual perception과 유사하더라. 이걸 이용해서 image를 perceptual space로 transform 할 수 있을까?
- 효과는 굉장했다.

- Perceptual Loss
- Image Transform Network: input image의 transform된 이미지를 뱉어낸다.
- Loss Network: transform된 이미지와 style target / content target을 각각 비교하여 loss를 계산한다.
- pre-trained (on ImageNet) VGG model을 사용하였다.
- Image Transfrom Network를 학습하는 동안 frozen 시킨다.

- Feature Reconstruction Loss
- output image와 content target image 각각이 loss network에서 만든 feature map을 이용하여, 이들 사이의 L2 loss를 계산한다.

- Style Reconstruction Loss
- output image와 style target image 각각이 loss network에서 만든 feature map을 이용하여 gram matrix를 만들고, 이들 사이의 L2 loss를 계산한다.
- 이때, 다양한 layer에서 뽑아온 feature map(과 이를 이용하여 만든 gram matrix)들을 사용한다.
- gram matrix: feature map에서 필요없는 spatial한 정보는 지우고, feature map의 statistic한 정보만을 포함한다. 각 feature map을 (C x (W*H)) size로 만든 후, 이 둘을 matmul 하여 결국 C x C size를 갖는다.

Various GAN applications
Deepfake
- 사람의 얼굴 또는 목소리를 다른 얼굴 또는 목소리로 바꾸는 것
- GAN을 사용하면 쉽게 fake video/image를 생성할 수 있다.
- GAN을 이용한 범죄를 막는 것이 중요한 문제로 떠오르고 있다.
Face De-Identification
Face De-Identification
- Live Face De-Identification in Video, 2019, ICCV
- 인간의 face image를 살짝 수정하여 인간에게는 비슷해보이지만, 컴퓨터는 identify가 어렵게 함으로써 privacy를 보호한다.

Face Anonymization with passcode
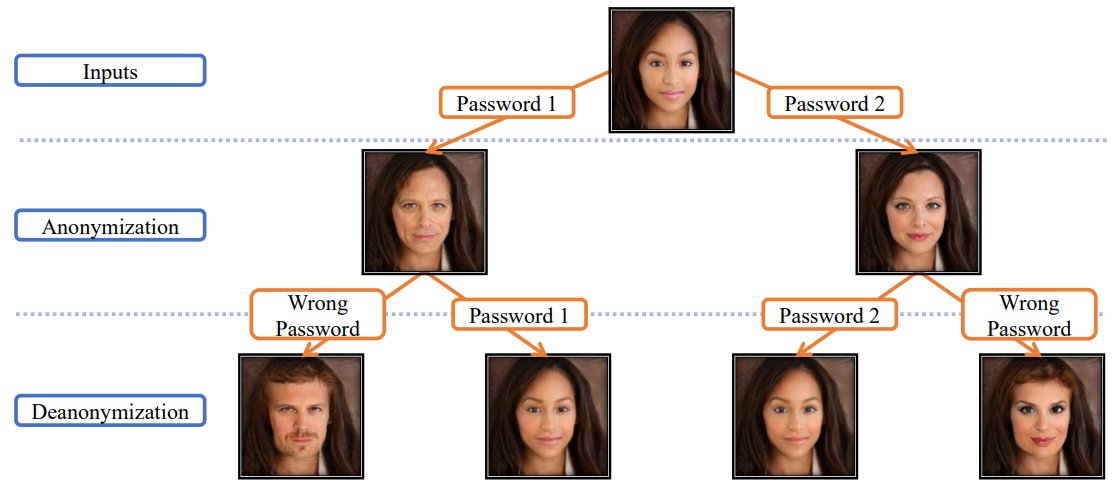
- Password-conditioned Anonymization and Deanonymization with Face Identity Transformers, 2020, ECCV
- Specific한 passcode가 있어야만 original image에 접근할 수 있도록 함.
Video Translation (Manipulation)
Pose Transfer
- Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis, 2019, ICCV
- Input을 source image와 같은 pose로 만들 수 있다.

Video-to-Video Translation
- Video-to-Video Synthesis, 2018, NeurIPS
- Segmentation map video를 input으로 받은 후, realistic 한 video를 뱉어낸다.

22.10.18
- 오늘은: (이고잉님의 Git 특강) + (8강 블로그 정리) + (과제 4) + (피어세션: Stat 110 질문 공유 + 과제 4 결과 공유) + (5시 30분 팀 빌딩 미팅)
- 내일은: (10, 11강 수강) + (피어세션) + (과제 5) + (9, 10, 11강 블로그 정리..?)
- 목: (이고잉님의 git 특강) / (마스터클래스) ㅡ> 공부할 수 있는 시간 = 오후 1시간
- 금: 스페셜 피어세션 / 피어세션 / 오피스아워 ㅡ> 공부할 수 있는 시간 = 오전 2시간 / 오후 2시간
- 왜 이리 바쁜 것 같지?
- 확실히 블로그에 정리를 하는게 학습에 도움이 되는 것 같다. 백지 공부법이랑 비슷한 느낌. 그리고 사진을 넣을 때 해당 내용을 발표한 논문을 찾아보다가 궁금한게 생기면 바로바로 찾아볼 수도 있다.
- 컨택 메일을 보내야 되는데, 그 전에 CV 정리를 먼저 해야된다. 근데 맨날 피곤해서 회고가 끝나면 잠들어버린다. 그리고 늦게 일어난다. 그러면 일어나자마자 샤워를 하고, 일정이 시작된다. 이러다 금방 지치겠는걸? 내일은 점심시간에 카페로 이동해서, 오후에는 계속 밖에 있어야겠다.