
Date: 22.12.19
출처가 명시되어 있지 않은 모든 이미지의 지식재산권은 재단법인 네이버커넥트에 귀속됩니다.
FCN
원문: Fully Convolutional Networks for Semantic Segmentation, Jonathan Long et al., 2014
Fully Convolutional Networks for Semantic Segmentation
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build
arxiv.org
Semantic Segmentation에 사용되는 대표적인 딥러닝 모델로, 다음과 같은 세 가지 특징을 갖는다.
1. VGG backbone을 사용했다.
2. VGG network의 fc layer를 convolution layer로 대체하여 사용한다.
3. Transposed Convolution을 이용하여 pixel wise prediction을 수행한다.
왜 fc layer를 convolution layer로 바꾸었을까? fc layer를 통과한 feature map은 위치 정보를 잃게 되기 때문이다. 이로 인해, pixel 별로 class를 결정해주어야 하는 semantic segmentation에서는 사용하기 어렵다. 따라서, 각 pixel의 위치 정보를 해치지 않은 채로 특징을 추출할 수 있는 1x1 convolution 연산으로 대체했다.
전체 구조는 아래와 같다. convolution 연산을 통해 특징들을 추출한 후, transposed convolution 연산을 통해 원본 사이즈와 같은 크기의 prediction map을 만들어낸다..
이제, Transposed Convolution 연산에 대해 알아보자. Upsampling, Deconvolution, Transposed Convolution이라는 표현이 자주 혼동되어 사용되지만, upsampling은 interpolation등의 방법을 모두 포함하는 상위 개념이고, deconvolution은 이 연산이 convolution의 역연산이 아니기 때문에 (Stanford CS231n에서는) 틀린 표현이라고 한다. 이후 등장하는 upsampling, deconvolution은 모두 transposed convolution이라고 생각하면 된다. 그럼 이제, 왜 Transposed Convolution이라 불리는지 알아보자.
Convolution 연산은, 개념적으로는 filter를 이동시켜가며 합성곱을 수행하는 것이지만, 연산 속도를 위해 아래와 같이 filter를 sparse matrix 형태로 바꾼 후 matrix multiplication을 수행하도록 구현되어 있다고 한다. 그 과정은 아래와 같다.
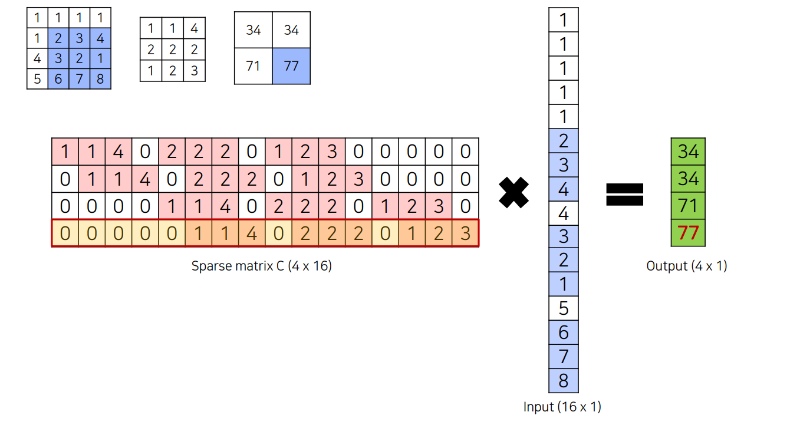
이때, sparse matrix C를 transpose하면, 정확히 우리가 생각한 연산이 수행된다. 그러니, 앞으로는 이 연산을 Transposed Convolution 이라고 부르자.


Transposed Convolution 연산의 의미는, Convolution 연산과 마찬가지로 학습이 가능한 parameter를 통해 줄어든 feature map의 크기를 다시 키워줄 수 있다는 것이다.
FCN에서, input은 5번의 maxpooling을 거치게 되므로, 마지막 feature map의 크기는 원본보다 가로, 세로가 1/32로 줄어든 상태이다. 따라서, 마지막 Deconv Layer에서 32배로 scale-up 시켜준다. 이때, 정보량은 그대로인 채로 resolution을 높이는 과정에서 smooth한, 경계가 명확하지 않은 결과를 보이게 된다. 따라서, 저자들은 최종 output과 이전 block에서의 정보를 모두 이용하여 최종 결과를 만들 수 있는 방식을 제안한다. 그 과정은 아래와 같다.

최종 결과를 만들기 위해 사용하는 정보의 양이 많을수록 보다 경계가 명확히 표현되는 결과를 보이는 것을 확인할 수 있다.

22.12.19
오늘은 : 1~5강 / 미션 1, 2 (솔루션 확인) / Stat 110 19강
내일은 : 학습 정리 먼저하고, 강의 마저 듣기 / 멘토링
이번주에는 : 아침에 뭐할지 미리 정하고 자기 / 학습 정리 꾸준히 하기 / 이력서, 포트폴리오, CV 한번에 정리하기